Нейронные сети. Вопросы экспертам. - страница 5
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Согласен. Вот я и спрашивал, какая взаимосвязь между ошибкой и профитом, желательно на ООС....)))
too joo вы говорили, что нуед результат может быть связан с нормализацией данных, я и ответил, что ее не было.
ЗЫ Я согласен с Лео, что не всегда критерий ошибки определяет конечный профит, но в той задаче, которая стоит перед мной сейчас важна именно ошибка. Сегоджня вчером выложу прогноз который сделала сетка, что бы узнать мнение других о качетсве прогноза и возможных улучшениях)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Можете не тратить свое время, т.к. между "хотеть" и "получить" разница совсем не философская, хотя формулируется философскими понятиями о "субъективном" и "объективном".
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Однозначно сетка должна стремиться к профиту на OOS. Иначе нет никакого смысла.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Reshetov писал(а) >>
Однозначно сетка должна стремиться к профиту на OOS. Иначе нет никакого смысла.
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Для трейдинга среднеквадратичную ошибку не использую, т.к. она характеризует только качество подгонки.
Поэтому ошибка на выборке никак не должна стремиться
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?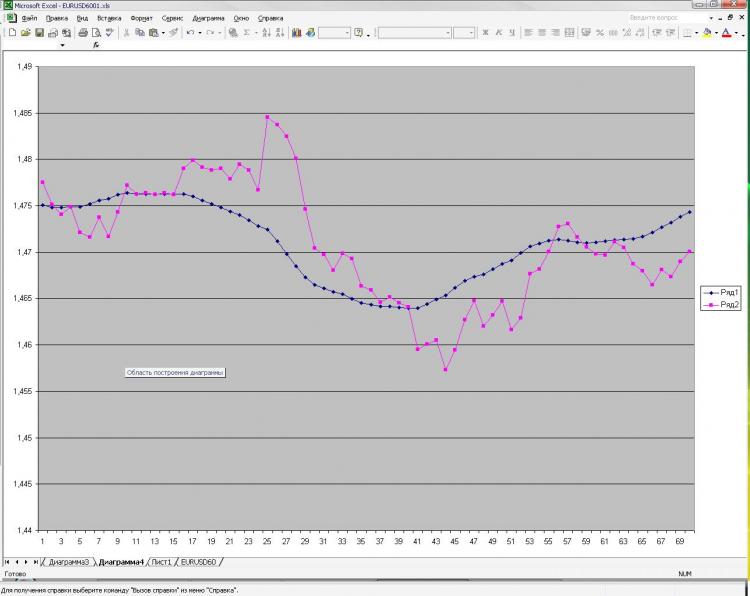
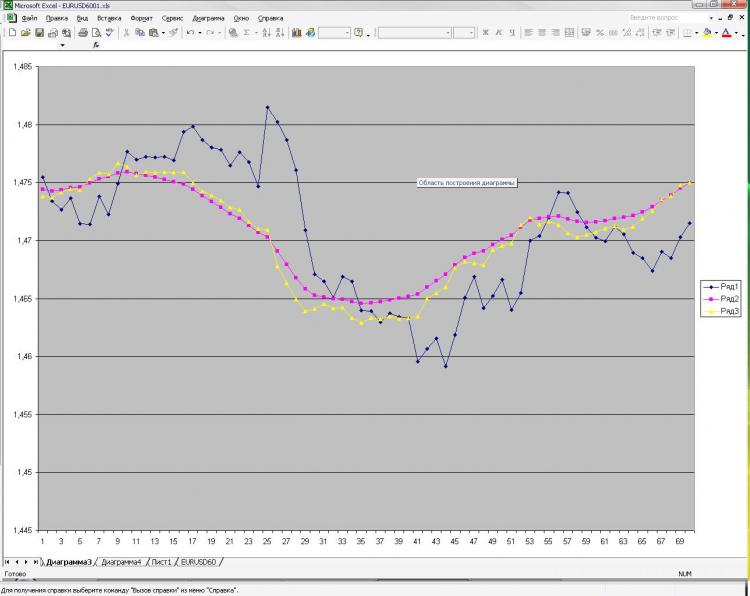
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
Вы описали задачу аппроксимации. Двух "опорных" точек недостаточно для описания формы. К тому же, подаете ещё по одной точке клоуз, которые не только кривизну, но и прямую линию не описывают. Попробуйте, по крайней мере 3 точки из каждого набора входящих параметров. Т.е. три точки ЕМА и три точки клоуз, и того - 6 входных нейронов, в скрытом слое от 6 до 12 нейронов. Большее количество нейронов в скрытом слое для данной задачи не целесообразно.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Давайте сюда выборку, попробую в Statistica'е